23 May 2014
edit on github
Cancellation tokens
This release comes with great feature for long-running jobs: cancellation tokens. They are like CancellationToken class, but for background jobs.
Previously, you was not able to stop a running job by using Requeue or Delete methods of the BackgroundJob class, or by clicking a button in HangFire Monitor. Its state was changed, but the job is still running. And running… And running… Nobody waits for it, why it is not stopped yet?
Job cancellation tokens provide ThrowIfCancellationRequested method that throws OperationCanceledException if a job was canceled due to:
- Shutdown request – executed on
BackgroundJobServer.Stop method invocation. Performed automatically when ASP.NET application is shutting down.
- State transition – the state of the job has been changed, and it is not in the
Processing state now. BackgroundJob.Delete, BackgroundJob.Requeue as well as all Monitor interface buttons lead to the job cancellation (in case it is running).
To use cancellation tokens, you need to add just one parameter of type IJobCancellationToken to a target method:
public static void Cancelable(
int iterationCount,
IJobCancellationToken token)
{
try
{
for (var i = 1; i <= iterationCount; i++)
{
// Loop breaker
token.ThrowIfCancellationRequested();
Thread.Sleep(1000);
Console.WriteLine(
"Performing step {0} of {1}...",
i,
iterationCount);
}
}
catch (OperationCanceledException)
{
Console.WriteLine("Cancellation requested, exiting...");
throw;
}
}
Then, create a background job:
BackgroundJob.Enqueue(
() => Cancelable(1000, JobCancellationToken.Null));
To be able to test target methods, or to add the support of cancellation token to your old jobs, you can use the JobCancellationToken class:
public void Test()
{
var token = new JobCancellationToken(true);
Cancelable(10, token);
}
Hanging jobs
This release solved another problem. On some job queues (Redis, SQL Server, but not MSMQ) it is not possible to apply transaction just to fetch a job from a queue, hide it from another workers, and delete it on successful processing or place it back to a queue on failure or process termination.
To mimic this behavior, HangFire uses atomic get/set commands: update with output clause in SQL Server and BRPOPLPUSH in Redis. That is why other workers don’t see just fetched job. But in case of process termination, all jobs will remain in invisible state. To fight with this, there is a component on a server, who seeks invisible jobs and decides what to do with them.
Unfortunately, there is no way to determine whether a job was aborted by a process termination, or it is still working. To separate these cases, the component checks the fetching time of a job and compares it with current time. If the result is greater than InvisibilityTimeout, then we should trait the job as hanged, and return it to its queue. InvisibilityTimeout defaults to 30 minutes to be sure that the job processing was aborted.
When ASP.NET issues shutdown request and gives background jobs 30 seconds to die, some of them may be aborted by ThreadAbortException. In previous releases this lead to the fact that background job may stay in Invisible state on regular shutdown, and this sometimes increase the latency of job processing.
In this release HangFire make an attempt to place aborted job back to the start of its queue on this exception, and it will be started again immediately after application restart on success, and after InvisibilityTimeout on failure.
When the feature of re-queueing jobs on ThreadAbortException plays together with job cancellation tokens, it means that you greatly decrease the latency of background job processing, because the probability of using InvisibilityTimeout is greatly decreased.
TL;DR
Use job cancellation tokens where possible to ensure that your jobs are shutting down gracefully, and you greatly decrease the probability of high latencies in your background job processing.
Changes
- Added – Cancellation token for job methods that throws on server shutdown and job aborts.
- Added – Place interrupted job back to its queue if possible.
- Fixed – Can not delete jobs when method or class was removed.
- Fixed – NullReferenceException in Monitor.
- Fixed – SqlException when changing state of a job with absent target method.
Links
21 May 2014
edit on github
Batch operations
Got tired to aim and click the Retry button on each failed job? It is much easier now, look at this:
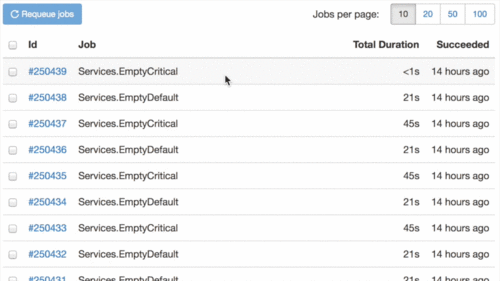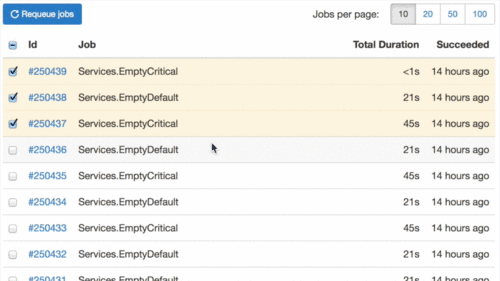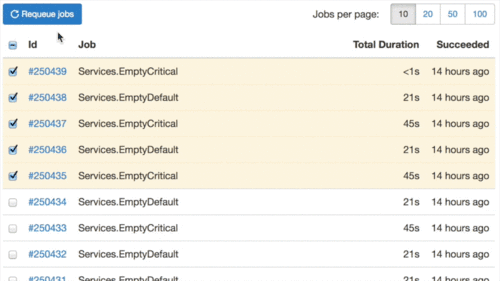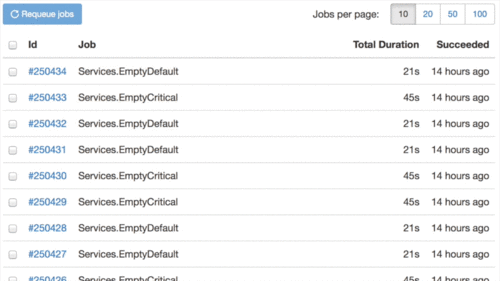
Never knew that animated GIF optmimzation is so boring, especially for the first time.
You are also able to select all jobs in one click. Many thanks to GitHub Issues – they gave me an idea of how to make an ideal implementation of multiple items selection.
Additional metrics
When you write the code, it is important to have an instrument to measure the performance time. ASP.NET has different diagnostic tools for this task – Glimpse, MiniProfiler and other useful ones. But they are aimed to provide information about requests only, and almost useless for background jobs – they are being executed outside of a request.
I’ve implemented simple diagnostic feature (and not the replacement to full-stack performance profilers, such as dotTrace) for HangFire Monitor, and now you are able to see the following timings in HangFire Monitor:
- Duration – job method + all filters performance time.
- Latency – delay between the job creation and method invocation. This metric shows you background job invocation overhead.
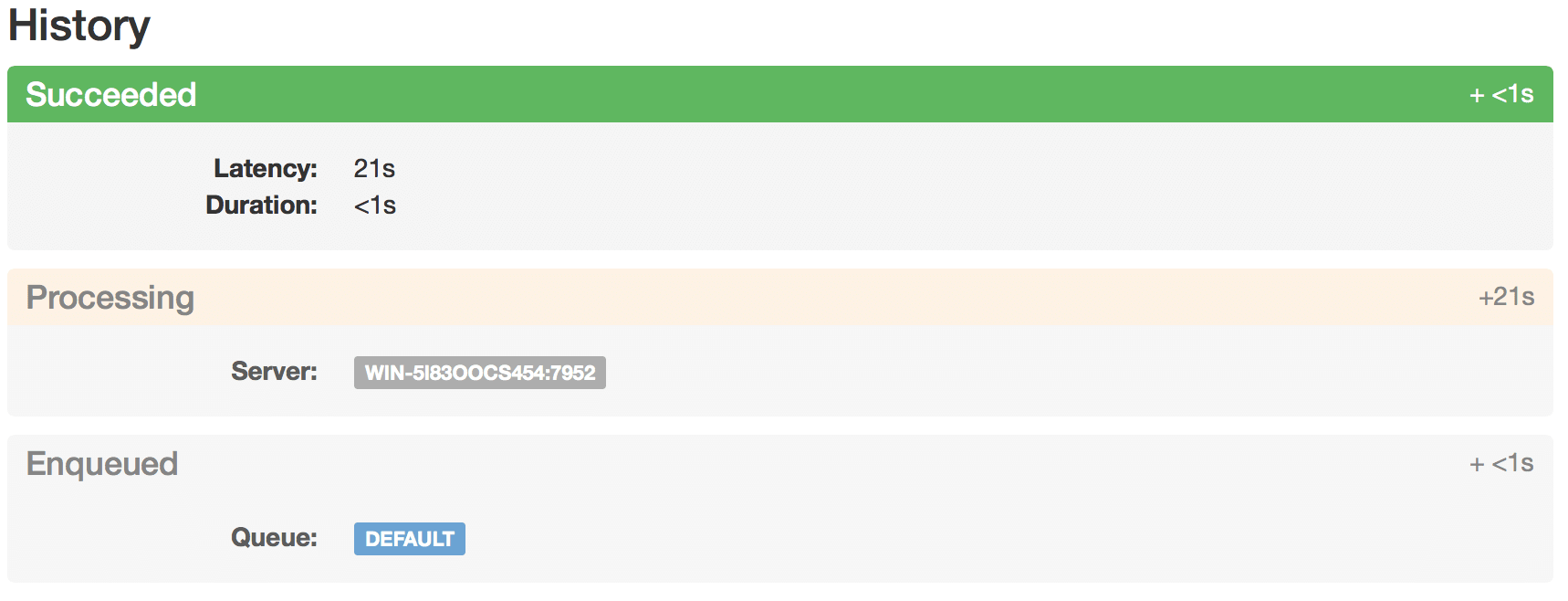
As you can see, you can also watch the delays between state transitions. All timings have minimum resolution in 1 second. This resolution caused by using unix timestamps in HangFire. We need to change the things, but a bit later.
These metrics are added to the SucceededState, so they are also available to state filters.
DisableConcurrentExecution filter
This filter places a distributed lock in the beginning of a method performance and releases it after it was completed using the IServerFilter interface. The type and method name are being used as a locking resource. Each storage uses its own distributed lock implementation:
- SQL Server uses
sp_getapplock stored procedure;
- Redis implementation uses the technique described in its documentation.
[DisableConcurrentExecution(timeoutInSeconds: 10 * 60)]
public void SomeMethod()
{
// Operations performed inside a distributed lock
}
The filter is very useful in situations when you are accessing/changing shared resources that does not provide built-in locking routines. Otherwise you should make argumentative decision between using locking system provided by the resource itself, and a custom distributed locking like this filter.
For example, in SQL Server it is better to consider using different isolation levels and table hints first.
Changes
- Added - Batch operations on jobs for HangFire Monitor.
- Added - Retry and delete buttons for almost every page of HangFire Monitor.
- Added - Duration and latency metrics for succeeded jobs.
- Added - Display state transition latencies on job details page.
- Added - DisableConcurrentExecution filter.
- Misc - Tables in HangFire Monitor received some love.
Links
17 May 2014
edit on github
Note. The following information may be outdated after 1.0 release. Please see the official documentation first.
Release notes
This release contains a bunch of new features, that complete the background job workflow (Deleted state), make it without additional latencies (MSMQ support) and inform you about failures in-time:
- Added - MSMQ queues support for SQL Server job storage.
- Added - “Deleted” state for jobs, when we don’t want to process them anymore.
- Added - “Requeue” and “Delete” buttons on a job page in HF Monitor.
- Added - Logging job failures: warning - there is a retry, error - no attempts left.
- Added -
BackgroundJob.Requeue and BackgroundJob.Delete methods.
- Changed - Set
InvisibleTimeout back from 5 to 30 minutes.
- Changed -
RetryAttribute is deprecated. Use AutomaticRetryAttribute instead.
As always, the new version of HangFire can be installed via NuGet Gallery. Here is the package list.
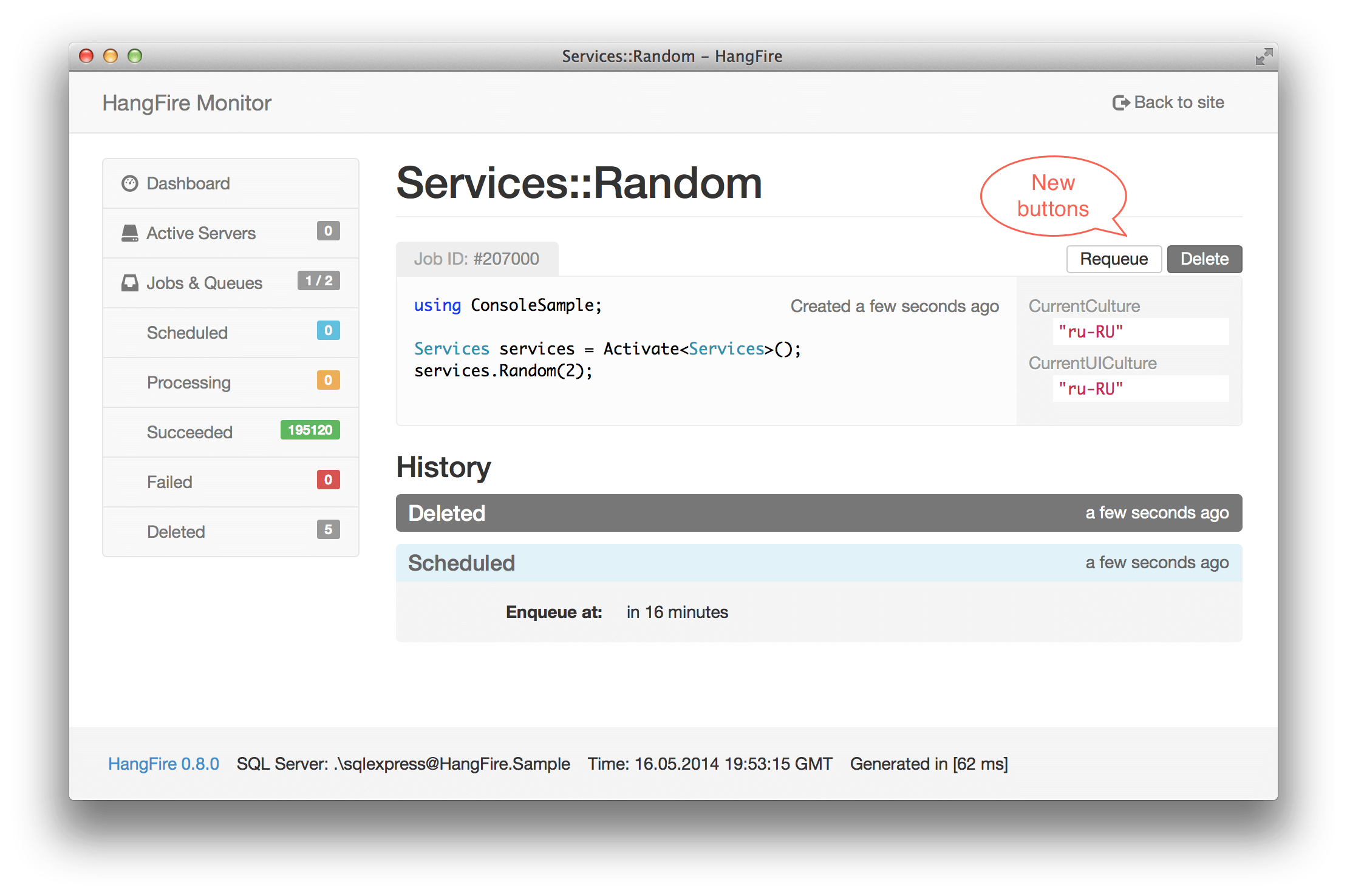
Deleting jobs
There is a new state – DeletedState, and some methods to perform the deletion – BackgroundJob.Delete and IBackgroundJobClient.Delete. When you are using these methods, a job is not being actually deleted, there is only state transition. Jobs in the deleted state expire after some delay (as succeeded jobs).
The operation does not provides guarantee that the job will not be performed. If you deleting a job that is performing right now, it will be performed anyway, despite of calls to delete methods.
Usage
If you want to delete job despite its current state, do the following:
var jobId = BackgroundJob.Enqueue(() => Console.WriteLine("Hello, world!"));
BackgroundJob.Delete(jobId);
// or
IBackgroundJobClient client = new BackgroundJobClient();
client.Delete(jobId);
If you want to be able to handle only deletion from exact state, for example, only from FailedState (because it may change after you click and before it will be deleted), you can specify it:
var jobId = BackgroundJob.Enqueue(() => Console.WriteLine("Hello, world!"));
BackgroundJob.Delete(jobId, FailedState.StateName);
// or
IBackgroundJobClient client = new BackgroundJobClient();
client.Delete(jobId, ScheduledState.StateName);
Manual deletion
Job details page now contains Requeue and Delete buttons (other pages also have these buttons). So, you can requeue and delete your jobs at any time:
MSMQ support for SQL Server storage
SQL Server job storage implementation does not require you to learn and install additional technologies, such as Redis, for projects to use HangFire. However, it uses polling to get new jobs that increases latency between the creation and invocation process (see also this feature request).
The MSMQ implementation, that was introduced in HangFire 0.8.1, replaces only the way HangFire enqueues and dequeues jobs. It uses transactional queues to delete jobs only upon successful completion, that allows to process jobs reliably inside ASP.NET applications. MSMQ queues contain only job identifiers, other information is still persisted in the SQL Server database.
Advantages of using MSMQ
- No additional latency. It uses blocking calls to fetch jobs – they will be processed as soon as possible.
- Immediate re-queueing of terminated jobs. If the processing was terminated in the middle, it will be started again immediately after application restart. SQL Server implementation uses InvisibleTimeout to distinguish between long-running and aborted jobs.
Installation
MSMQ support for SQL Server job storage implementation, like other HangFire extensions, is a NuGet package. So, you can install it using NuGet Package Manager Console window:
PM> Install-Package HangFire.SqlServer.MSMQ
Usage
To use MSMQ queues, you should do the following steps:
- Create them manually on each host. Don’t forget to grant appropriate permissions.
- Register all MSMQ queues in current
SqlServerStorage instance.
var storage = new SqlServerStorage("<connection string>");
storage.UseMsmqQueues(@".\hangfire-{0}", "critical", "default");
// or storage.UseMsmqQueues(@".\hangfire-{0}") if you are using only "default" queue.
JobStorage.Current = storage;
To see the full list of supported paths and queues, check the MSDN article.
Limitations
- Only transactional MSMQ queues supported for reability reasons inside ASP.NET.
- You can not use both SQL Server Job Queue and MSMQ Job Queue implementations in the same server (see below). This limitation relates to HangFire.Server only. You can still enqueue jobs to whatever queues and watch them both in HangFire.Monitor.
The following case will not work: the critical queue uses MSMQ, and the default queue uses SQL Server to store job queue. In this case job fetcher can not make the right decision.
var storage = new SqlServerStorage("<connection string>");
storage.UseMsmqQueues(@".\hangfire-{0}", "critical");
JobStorage.Current = storage;
var options = new BackgroundJobServerOptions
{
Queues = new [] { "critical", "default" }
};
var server = new AspNetBackgroundJobServer(options);
server.Start();
Transition to MSMQ queues
If you have a fresh installation, just use the UseMsmqQueues method. Otherwise, your system may contain unprocessed jobs in SQL Server. Since one HangFire.Server instance can not process job from different queues, you should deploy two instances of HangFire.Server, one listens only MSMQ queues, another – only SQL Server queues. When the latter finish its work (you can see this from HangFire.Monitor – your SQL Server queues will be removed), you can remove it safely.
If you are using default queue only, do this:
/* This server will process only SQL Server table queues, i.e. old jobs */
var oldStorage = new SqlServerStorage("<connection string>");
var oldOptions = new BackgroundJobServerOptions
{
ServerName = "OldQueueServer" // Pass this to differentiate this server from the next one
};
var oldQueueServer = new AspNetBackgroundJobServer(oldOptions, oldStorage);
oldQueueServer.Start();
/* This server will process only MSMQ queues, i.e. new jobs */
// Assign the storage globally, for client, server and monitor.
JobStorage.Current =
new SqlServerStorage("<connection string>").UseMsmqQueues(@".\hangfire-{0}");
var server = new AspNetBackgroundJobServer();
server.Start();
If you use multiple queues, do this:
/* This server will process only SQL Server table queues, i.e. old jobs */
var oldStorage = new SqlServerStorage("<connection string>");
var oldOptions = new BackgroundJobServerOptions
{
Queues = new [] { "critical", "default" }, // Include this line only if you have multiple queues
ServerName = "OldQueueServer" // Pass this to differentiate this server from the next one
};
var oldQueueServer = new AspNetBackgroundJobServer(oldOptions, oldStorage);
oldQueueServer.Start();
/* This server will process only MSMQ queues, i.e. new jobs */
// Assign the storage globally, for client, server and monitor.
JobStorage.Current =
new SqlServerStorage("<connection string>").UseMsmqQueues(@".\hangfire-{0}");
var options = new BackgroundJobServerOptions
{
Queues = new [] { "critical", "default" }
};
var server = new AspNetBackgroundJobServer(options);
server.Start();
10 May 2014
edit on github
HangFire takes regular classes and regular methods to perform them in the background, because it is simple to use them:
BackgroundJob.Enqueue(() => Console.WriteLine("Hi!"));
This snippet says that the Console.WriteLine method will be called in background. But notice that the name of the method is Enqueue, and not Call, Invoke and so on.
The name of the method was chosen to highlight that invocation of a given method is only being queued in the current execution context and returns the control to a calling thread immediately after enqueueing. It will be invoked in a different execution context.
What does this mean? Several things, that may break your usual expectations about method invocation process. You should be aware of them.
Differences between local and background method invocation
Method invocation is being serialized
Before creating a background job, the information about the given method (its type, method name and parameter types) are serialized to strings. MethodInfo serialization process is absolutely invisible to a user, unlike arguments serialization.
Arguments are also serialized to string, but arguments serialization process uses the TypeConverter class. All standard classes like numbers, strings, dates and so on already have the corresponding TypeConverter implementation, but if you want to pass an instance of a custom class as an argument, you should write the custom converter first.
// Does not work until you implement the custom TypeConverter.
BackgroundJob.Enqueue(() => CheckArticle(new Article()));
Furthermore, serialized arguments can take more space, and it often is more efficient to pass database identifiers or file names instead of their contents.
Execution context is being changed
In the simplest case, such as using ThreadPool.QueueUserWorkItem or Task.Factory.StartNew methods, only thread is being changed. But in HangFire, you can use different process, or different server to process background jobs.
So, the execution context term includes not only thread context, request context and so on, but also static data, including local locks, local filesystem, etc.
That is why if you are querying data inside a background job that corresponds to the execution context where the job was enqueued, it may fail. If you need to pass the current state to a job, use arguments or shared storage.
public void Method()
{
// Does not work, use distributed locks.
lock (_object) { /* ... */ }
// Does not work either, pass data as an argument.
if (HttpContext.Current.Request.IsLocal)
{
// Processing
}
}
Delayed invocation
Background job methods are not invoked immediately. It is placed on a queue and waits until any worker pick it up. This leads to an undefined start time and end time.
Undefined start-up time
Your method can be invoked tomorrow, after two weeks or six months (always true for scheduled jobs, but works with “fail-deploy-retry” practice as well). If it is true even for regular method calls, that application data can be changed or arguments can become stale during the method invocation, especially in a highly concurrent web applications, the probability of these situations in background job processing is very high.
Always double-check the data that you pass as arguments and think about its changing nature. Here are some examples:
- You want to publish an article tomorrow, think, what do you need to do: publish its current state, or publish the article itself. In the most cases you’d choose to publish the article itself, changed or unchanged. That is why in this case you need to pass an article identifier as an argument.
- You want to check comments for spam and it is possible to change them. You are creating a new background job on each edit attempt. In this case, you need to check exactly the given text for each edit, so pass the whole text as an argument. And after the check is completed, you can compare this text with the current one. If it was changed, then don’t do anything.
Undefined end time
We are thinking about the end time, when we want to tell our users about the job was completed. If you do something inside the request processing synchronously, you can rely on that fact that this information will be available for a user immediately. That is why you can redirect her to a just created article page.
But when, for example, you are creating the same article in a background job, you can redirect user to a non-existing page yet, because you can not guarantee that the enqueued job will be processed in time.
Of course, you always can tune your system to perform background jobs as soon as possible, but you can not eliminate the delay between enqueue time and a real invocation completely.
So you need to think how to show yet unprocessed entities (with loaders, progress bars and so on), and how to report the job completion. For a latter task, you can always use polling, server push (for example, using SignalR), or force users to reload the page manually.
Delayed failure
If you pass user input as an argument of your job, you should validate them first. Otherwise the job will always fail, retry, fail again, retry again and so on. It will never be completed without manual intervention.
You can disable automatic retry on failure, but there is another problem – since the immediate invocation is not guaranteed (see the section Delayed invocation), your user may leave the site and she will not be able to correct the data.
So, validate your arguments early, and instead of doing this:
public ActionResult CreateComment(string message)
{
BackgroundJob.Enqueue(() => CheckComment(message));
...
}
public void CheckComment(string message)
{
if (message == null)
{
throw new ArgumentNullException("message");
}
// Processing
}
Do this:
public ActionResult CreateComment(string message)
{
if (message == null)
{
return ValidationError(message); // Pseudo-code
}
BackgroundJob.Enqueue(() => CheckComment(message));
...
}
public void CheckComment(string message)
{
// But you can leave the guard condition here.
// Processing
}
Method can be called multiple times
Your method can be retried manually (through the Monitor interface) or automatically on failure (i.e on unexpected exception that is unhandler by the method itself).
So, be prepared for this situation. Try to make all your background job methods idempotent. Be prepared, in very rare cases, that your background job can fire multiple times.
You can always disable the automatic retry feature by applying the [Retry(0)] filter to the exact method or globally. But to successfully fight with ASP.NET unexpected application domain unload in the middle of a job processing, HangFire retries them automatically despite of the given attribute. But don’t worry too much, these cases happen very rarely.
But as a general rule remember, that your job will be performed at least once. You can test your job for idempotence by calling it multiple times and compare the result:
public void TestIdempotence()
{
// Arrange
// ...
// Act
YourMethod();
YourMethod();
// Assert
// For example, check that records were not duplicated.
}
Method may become unavailable
Your application can be redeployed with a different code base after a background job was enqueued. That is why you should change the signature of your background job methods carefully.
You can safely change parameter names, but the following things will lead to a broken job (however you are able to fix it and re-deploy the application):
- Addition and removal of method parameters.
- Parameter type changes.
- Parameter reordering.
- Method name changes.
- Method’s type name changes.
- Method removal.
- Method’s type removal.
- Type’s namespace changes.
- Type’s assembly changes.
Of course you can do all the above things, if there are no jobs in a storage. But instead of doing this, add a new method without touching the old one and call the new method from the old one until all old jobs become processed:
public void OldMethod(string arg1, int arg2)
{
// Redirect
NewMethod(arg1, arg2, DefaultValueForArg3);
}
public void NewMethod(string arg1, int arg2, double arg3)
{
// Real processing
}
Summary
There are a lot of differences between local and background method invocation, but you likely know the most of them, because they relate to asynchronous and concurrent programming as well.
If you have any questions, ask them in the comments form below the post or start a new topic on http://discuss.hangfire.io if you want to share code snippets.
02 May 2014
edit on github
Today I’ve pushed the next version of HangFire project that allows to process background jobs inside ASP.NET applications in a reliable way.
Although this release contains only one new feature that is visible for all users (security improvements), it brings HangFire closer than ever to the version 1.0. But let’s see the new changes.
Note. The conceptual part of the following information is correct, but implementation details changed since version 1.0. Please, see the documentation instead of relying this information.
Remote requests are denied by default
HangFire has integrated monitoring system that shows you information about background jobs and acts as an ASP.NET’s IHttpHandler. Registration is performed by automatically changing the web.config file during the installation of the HangFire.Web package (it is a dependency of HangFire bootstrap package) by NuGet Package Manager.
This HTTP handler displays the internals of your application. Furthermore it offers to interact with this internal state: background jobs can be retried, possibly removed, scheduled earlier than necessary and so on. What if it become available for malicious users? It is hard to guess the actual consequences for a wide range of applications, but it is simple to understand that this behavior is highly undesirable.
The automatics greatly simplifies the installation process, but performs it on the quiet, making it simple to overlook that Monitor handler is ever exist or requires additional set-up. So, it is required to provide strong rules that work by default.
To solve this problem, we need to authorize users. ASP.NET applications have authorization feature by default, that is based on user names or their roles. But it is impossible to guess what user names and roles uses your ASP.NET application (if your application uses them at all). So, we need more simple solution.
The simplest solution is to block all remote requests by default using the Request.IsLocal property. Local requests are accepted as usually, and this decision does not bring problems for application developers. Another libraries, such as Elmah or Glimpse are also using this authorization policy by default.
The policy can be configured from the appSettings section of web.config file – I don’t want to introduce separate configuration section for a single setting.
Disable remote access to HangFire Monitor (by default):
<appSettings>
<!-- You can also remove this line to keep the default settings -->
<add key="hangfire:EnableRemoteMonitorAccess" value="false"/>
...
</appSettings>
Enable remote access to HangFire Monitor:
<appSettings>
<add key="hangfire:EnableRemoteMonitorAccess" value="true"/>
...
</appSettings>
Granting or denying access via ASP.NET authorization
Remote Monitor access policy is good. But once your application is deployed to production environment, you need to be able to access Monitor, otherwise it is useless.
Elmah library author and contributors conducted a deep investigation on a topic and proposed the solution to provide use ASP.NET authorization for such registered handlers:
- The handler registrations need to be moved under the location tag. Having them outside does not secure access sufficiently.
- The location element’s path attribute carries the same value as the path attribute of the handler registrations. Unfortunately, it has to be repeated so if you change one, the others must be updated to match.
- The authorization element is where the authorization rules go and where you will want to selectively grant access.
So, starting from this version, HangFire Monitor HTTP handler is being registered under the location tag:
<location path="hangfire.axd" inheritInChildApplications="false">
<system.web>
<authorization>
<deny users="*" />
</authorization>
</system.web>
<system.webServer>
<handlers>
<add name="HangFire" path="hangfire.axd" verb="*" type="HangFire.Web.HangFirePageFactory, HangFire.Web" />
</handlers>
</system.webServer>
</location>
The configuration example above denies access to all users, but that is a good starting point. You will probably want to add rules that allow access to only specific users and/or roles. For example, you might have a role for administrators and developers called admin and dev, respectively. To allow users that are members of either role, you could configure the authorization section above as follows:
<authorization>
<allow roles="admin" />
<allow roles="dev" />
<deny users="*" />
</authorization>
But to enable these rules, you need to set-up ASP.NET Authentication using, for example, the new and shining ASP.NET Identity project.
Moving closer to 1.0
This version contains 300+ new unit tests, their total number is 550, and the test coverage of HangFire.Core.dll is 99%. Although this does not say that HangFire is 100% bug-free, this is an indicator of the fact that the most code is tested and it is fully unit testable. New features can be added much faster. To do this, I’ve completely rewritten the Server subsystem that resulted in a more clean application model.
Full unit testability was one of the goals I wanted to achieve, and the fact that it requires a lot of breaking changes stopped me even to think about production-ready version. I want to use semantic versioning and do not want to have HangFire 28.0 in a few months.
Now I’ve started to think about production readiness, but I need a lot of feedback to give any stability guarantees.
Recently I’ve launched a new forum for HangFire to replace unnoying (for me) Google Groups – http://discuss.hangfire.io. It is modern, clean and easy to use, based on Discourse. So, have ideas or problems? Let’s discuss!